Flight Software at AstroForge
Matt Gialich
Flight software is the software that runs on the spacecraft. Our software is successful if it keeps the spacecraft within thermal and power limits, gracefully handles hardware failures, and provides clear and actionable information to operators on the ground.
The hardware setup
Before we can go too deep into the flight software, we need to understand the environment where it runs.

Outer space presents many challenges for computers. Cosmic rays from the sun or even outside the solar system are constantly traveling through space. If a cosmic ray hits a computer it can flip 1s in memory to 0s or vice-versa, leading to all sorts of problems. Imagine “spacecraft healthy” suddenly turning into “spacecraft unsafe”, or “turning right” incorrectly switching to “turning left” because of corrupted data. People and computers on Earth are protected from these rays by the Earth’s magnetic field, but in space - especially deep space - we have far less protection.
To avoid the dangers of radiation, many space missions make all of their computers radiation hardened, which means that the hardware is designed to prevent bit flips and other degradation from radiation hits. You should expect a radiation hardened computer to run, mostly without issue up to a certain radiation dosage. However radiation hardening often comes at a cost, and radiation hardened computers usually have less memory and compute than computers that aren’t radiation hardened.
Another approach is to use radiation tolerant computers - computers that should survive and not be permanently destroyed up to a certain radiation dose, but may experience bit flips and other data corruption. Radiation tolerant computers require more complex software to function properly, but often don’t sacrifice as much performance as radiation hardened computers.
For DeepSpace-2 we’re using both kinds of computers. We have two radiation-hardened SAMRH71 micro-controllers from Microchip and two non-radiation hardened NVIDIA Jetson AGX Xavier Industrial flight computers. At a high level, the micro-controllers allow us to stay power positive and transmit data, while the flight computers handle more compute-intensive processes like perception for tracking asteroids, data compression, and data storage.
DeepSpace-2 avionics are designed to be 1-fault tolerant. This means, we should be able to lose any single piece of avionics equipment - a computer, a harness/wired connection, a sensor, or an actuator like a reaction wheel, and still complete the mission. You can consider there to be two redundant sides or “strings” of the spacecraft: string A and string B. Each string has one micro-controller and one flight computer.
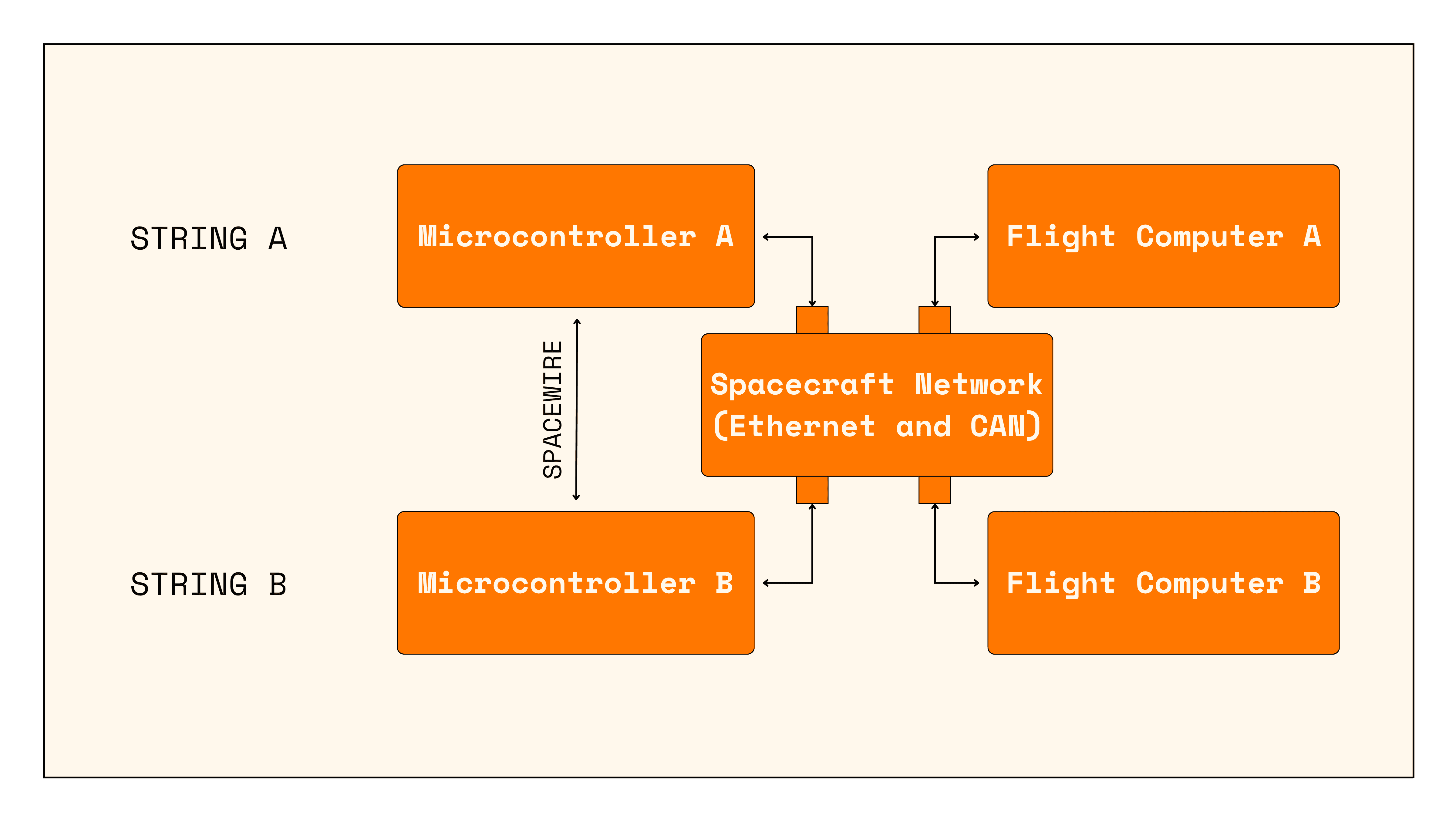
The micro-controllers
The two SAMRH71 micro controllers are responsible for power management, controlling the radios, and other safety-related tasks like thermal control and turning off the propulsion system in the case of an emergency.
If we stop getting status messages from the radio, the microcontroller will re-start it. If we get errors or stop hearing from the flight computer, then the microcontroller can restart it as well. If a part of the spacecraft is getting too hot, we can turn a heater off, and if a part of the spacecraft is getting too cold, we can turn a heater on.
The SAMRH71 has an ARM Cortex M7 processor and runs at 100 MHz. For comparison the flight computer processors run at 2.2 GHz. We write our software for the micro-controller with embedded rust and manage our tasks (radio control, power management etc.) with embassy executor. You can think of embassy executor as a light-weight system that we use to organize tasks on microcontroller. The embassy executor uses a fair scheduling policy, so all of the tasks (power management, radio control, heater control etc.) that run on the SAMRH71 have a chance to be scheduled before any task runs twice.

We carefully implement our tasks so that they relinquish the CPU before blocking another critical task. Consider downloading a very large image from the flight computer over the radio. If we keep sending data but never release the CPU, the tasks that check the temperature on the spacecraft won’t get a chance to run. Then we could be in a state where we need to turn a heater off, but we don’t read the temperature sensor that would tell us the spacecraft is getting too hot until its too late. That’s why we need to make sure that no tasks blocks the CPU for arbitrary amounts of time and periodically yields control to the other tasks.
We use the rust programming language on the flight computers, which gives us decent memory safety guarantees. Using rust on the micro-controllers as well allows for sharing common libraries for encoding and sending telemetry. Rust enforces memory safety by failing compilation for a broad range of memory errors that can be introduced by programmers, sometimes there are situations, like when hardware manages memory outside of the processor running rust, when the compiler won’t have enough information to determine that a memory access is safe. In those cases we can use the unsafe keyword to bypass this behavior. We need to write a good amount of unsafe rust on the micro-controllers for interacting with registers, but we can keep all of the code that interacts with that unsafe code memory safe.
The micro-controllers communicate with one another and peripherals via ethernet, controller area network (CAN), serial (i2c, UART, SPI), and SpaceWire. To maintain 1-fault tolerance, many devices will be powered if power is commanded on by either SAMRH71. Therefore to actually turn a device off in nominal operation, the SAMRH71s need to communicate so that both micro-controllers know to turn off power for a specific peripheral. The synchronization messages are sent between each SAMRH71 over both ethernet and CAN, so that SAMs can still co-ordinate if either CAN or ethernet connections on the spacecraft fail.
The flight computers
The flight computers are responsible for high-level tasks like taking pictures of asteroids, perception, reading from certain sensors, guidance navigation and control (GNC) software, controlling the propulsion system, storing data, and compressing data.
In nominal operation one flight computer is always on, and the other is a cold spare. If we have very low power, we’ll turn the flight computers off, and go into minimum power mode.
The flight computers run Linux (NixOS). The applications running on the flight computer are rust binaries managed by systemd. Each flight computer has two redundant 1 terabyte Non-volatile memory express (NVMe) drives for storage. As we stated earlier, unlike the SAMRH71 micro-controller the flight computers are not radiation hardened.
The Jetsons are more powerful for lower cost than a radiation hardened computer, but radiation can corrupt random access memory (RAM), boot-loaders, or persistent storage. If we take a radiation hit that causes enough damage, the SAMRH71 can reboot the flight computer, or we can switch to the cold spare.
To help mitigate radiation risks, we keep redundant copies of all the data on both drives and repair sections of the NVMEs if they get corrupted with the uncorrupted data from the other drive. A boot loader is the first piece of code that runs and “boots” the other software on the computer. If the boot loaders get corrupted by radiation, we won’t be able to load any other software. To prevent this class of errors, we also periodically check and overwrite our operating system boot-loaders if they don’t match the hash of the boot-loader that was originally loaded before the launch.
Nix and NixOS allow us to specify all of the dependencies we need on the flight computers in a declarative manner, rather than complicated build scripts. It also allows us to run certain programs in isolated nix shells to emulate specific environments for testing smaller pieces of code like single binaries.
Handling failures
In many domains, when software detects an error, you want to surface the error to the user and potentially disable the software entirely. When internet services backing a webpage fail, it may make sense not to show the webpage at all. When a software controlled physical device experiences a hardware failure, sometimes the best thing to do is prevent the device from running and wait for an expert to come and examine it.
After we launch DeepSpace-2, we will never command or get information about the spacecraft again other than through our software. As a result, the software needs to be robust to partial failure. If our inertial measurement unit that tells us which direction we’re pointing fails, we still need to do the best we can to point at the sun and stay power positive with our other sensors. If we become power negative, we need to keep our computers and radios on, read from sensors, and transmit through our radios so we have a chance to diagnose and send a command to fix the problem.
Flight computer micro-services
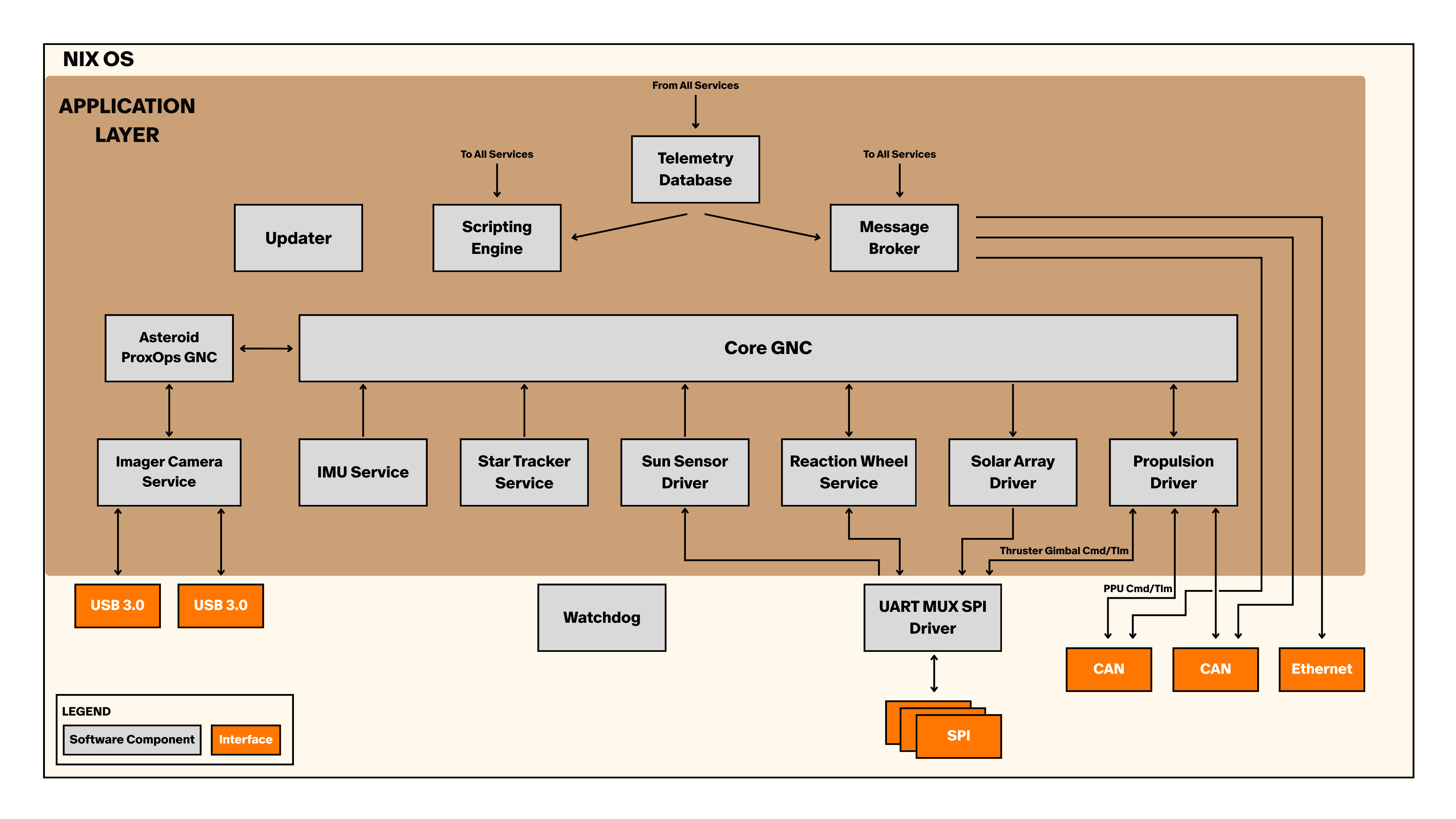
One of the major ways we make sure that our system is resilient to partial failures is by splitting the different tasks the flight computer needs to handle into isolated micro-services. On an operating system like Linux, a process is a program with its own virtual memory and other resources. On a personal computer a web browser would run as a process, while another program like a music player would run separately. If your web browser crashes, it doesn’t necessarily take the rest of your computer with it. The same concept applies on the flight computer.
When a process needs hardware resources, like to write to storage, or use the central processing unit (CPU), the operating system needs to schedule the process, so that no process can interfere significantly with the operation of all the other processes. On a computer like your desktop, many of the applications you use every day each run as their own process or a group of processes.
For DeepSpace-2 each micro-service also runs as a separate process, so that we can manage resources and isolate failures efficiently. For example on DeepSpace-2, the process that controls the electric propulsion system is different than the process that controls the reaction wheels. If there is any problem with the software or hardware in the propulsion system that causes that process to fail, we will still maintain control of the reaction wheels. Any process that exits (fails permanently due to a software error) is restarted with systemd.
Systemd is a “service manager” for linux. It allows us to define behavior of our micro-services, which each run as their own processes. Systemd let’s us define when services get restarted, how their logs get stored, and even how they interact with the CPU and other hardware.
We also use systemd to manage the relative priorities of processes. One of the most important services that runs on the flight computer is the core-gnc service. Core-gnc has the implementations of all of the GNC algorithms created by the GNC engineers to keep the spacecraft pointed in the right direction and headed toward the target asteroid.
We use the cpu weight cgroup controller to bias the scheduler toward core-gnc more often and we increase its priority via a property called niceness. This means that core-gnc is much more likely to be scheduled for cpu resources than less critical services like the camera service. The value of CPU weight is very similar to managing tasks on the microcontroller. If the camera service starts to use an extreme amount of CPU resources, we would rather the camera service be delayed than the guidance navigation and control system be delayed for a long period of time.
The spacecraft is mostly passively safe without the flight computers on, so we don’t yet need to enforce any stricter hard or soft real time requirements, but we can enforce stricter rules via linux modules PREEMPT_RT if necessary.
Communication Between Services and Storage
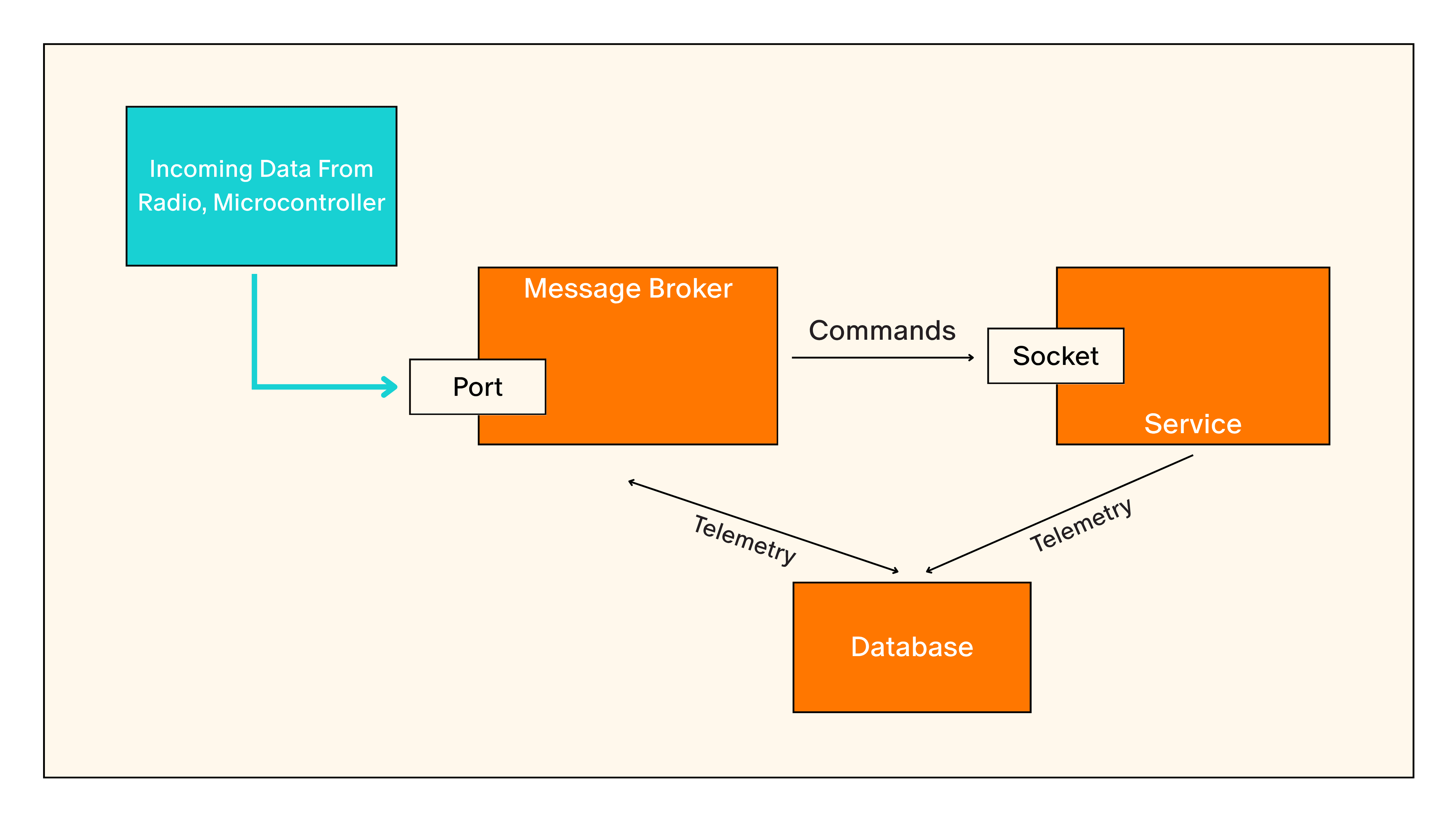
Splitting tasks on the flight computer into micro-services helps with isolating failures and resource management, but does introduce a bit of communication overhead.
Mircroservices (or just “services”) accept commands that are serialized with protocol buffers (protobufs) and they send and receive the protobufs via unix domain sockets. Each service also stores telemetry in a postgresql database that runs on the flight computer and is backed by a subvolume on the 1 terabyte NVME drives.
We use protobuf because data structure is simple to define, and its more compact than other simple formats like JSON or XML. Protobuf also is very well supported with code generation available in many languages including rust which we use in flight code and python which we use for automated testing.
While services can directly connect to one another on the flight computer, any commands or telemetry entering or leaving the flight computer from the ground or other devices must go through the message broker service. Message broker receives all commands from the ground and either executes them itself or forwards them to the correct service via the unix domain sockets.
Long distance radio calls
DeepSpace-2 is designed to travel as far as 20 million kilometers away from earth. It takes just under 67 seconds for light to reach the spacecraft at that distance. With our radio, power amplifiers, antennae, and available ground stations we can only support about 1000 bits per second downlink at our best ground stations at 20 million km. At 1000 bits per second, it would take over 35 minutes to download a 256 kilobyte image like the one in avionics stack at the top of the article, and a little over 18 hours to download a 1 minute youtube at 480p.
It takes a long time to exchange messages and we can’t send much data, but we still need to give operators clear and actionable information about the spacecraft. In order to do that, we need to send telemetry in a bandwidth efficient way.
After DeepSpace-2 separates from the second stage of the launch vehicle, we’ll be in an uncontrolled spin, also known as a tumble. While we’re tumbling the spacecraft will turn on, attempt to get the tumble under control with our reaction wheels, and begin transmitting data.
The faster we’re tumbling, the lower the amount of time when our antennae are pointed properly and we can connect to the ground. We can also tumble if we lose control of more than one reaction wheel. In a tumble - especially one at our maximum distance - we want to make sure that our state of health message is very robust to transmission errors, and that we get it very quickly.
Safe mode state of health
The state of health message from the SAMRH71 MCU is 12 bytes and includes information about power (load switches), heater states, and carrier/subcarrier lock for the radio:
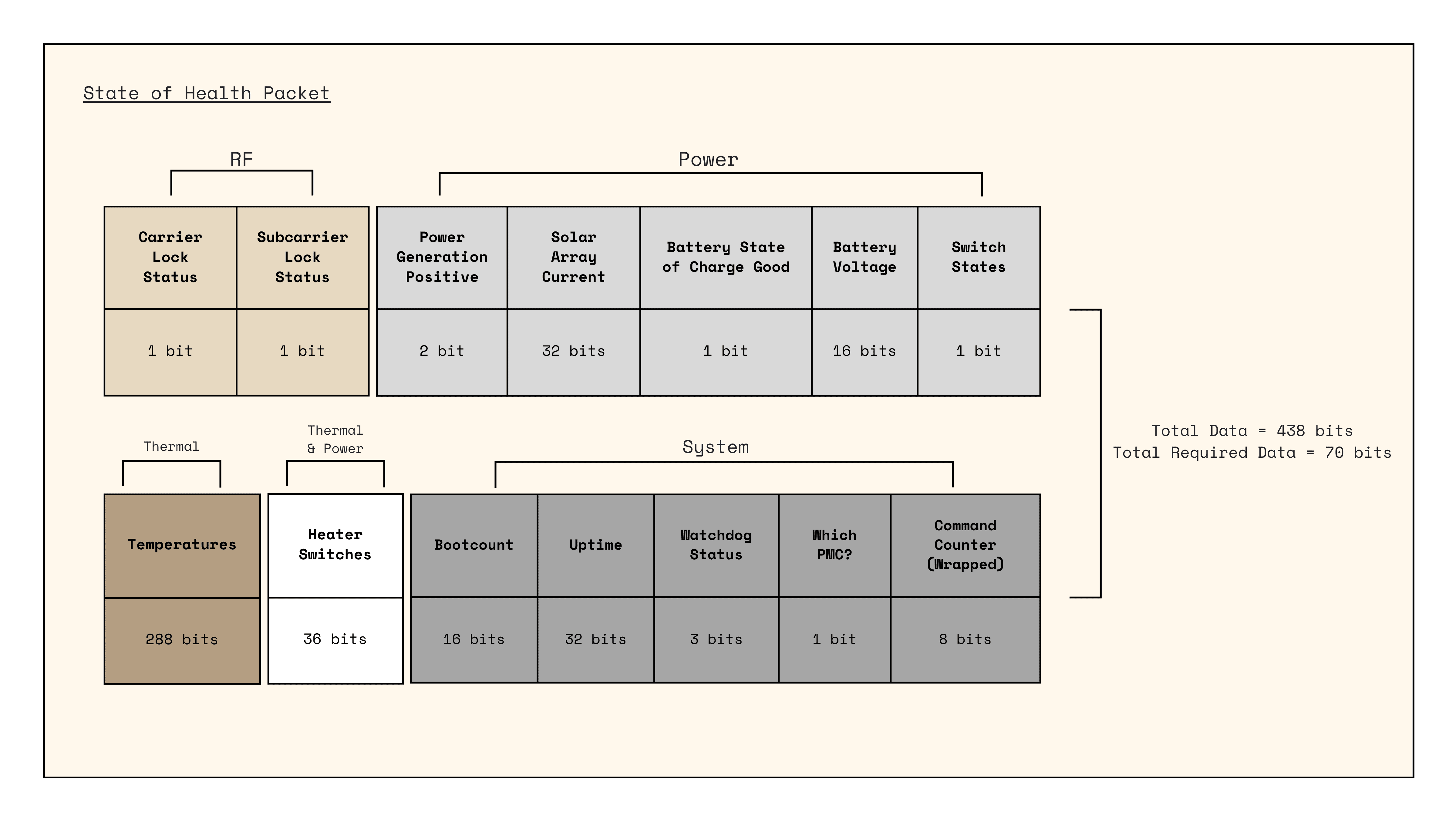
It also has a three byte Cyclic Redundancy Check (CRC) that we use to make sure the incoming data is not corrupted.
Furthermore to increase our signal-to-noise ratio and get and make sure the link closes with multiple ground stations at 20 million kilometers, we reduce the symbol rate to 400 symbols per second, which in turn reduces the bit rate to 400 bits per second of data with Binary Phase Shift Keying (BPSK).
We further add 70 bytes of Bose–Chaudhuri–Hocquenghem (BCH) and 1/2 K=9 Convolutional Codes, which will cause us to receive our state of health message and CRC in 1.2 seconds, well under the 5 second design requirement.
Flying Safe with the State Machine
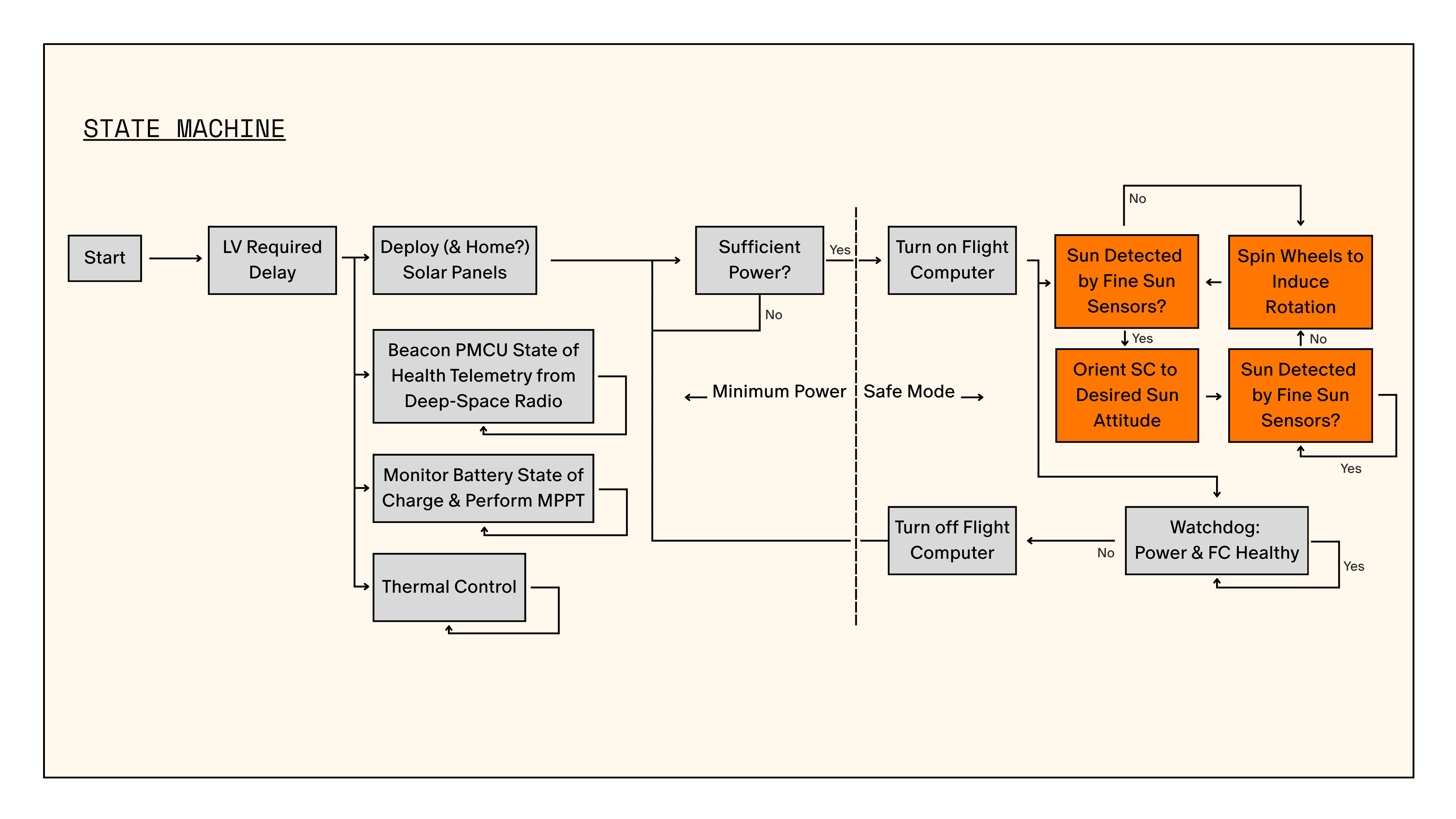
DeepSpace-2 operates with a state machine. That means that the spacecraft is always in some “mode” or state, and that events or commands can transition us into a different mode. We will discuss other modes in more detail in the future, but the two important modes on startup are Safe Mode and Minimum Power Mode.
We enter minimum power mode if we have very low power and need to turn off everything except what’s needed for communication, power management, and thermal control. If we turn everything off except what’s needed for survival, we can hopefully get enough power from the solar arrays to recharge the batteries and eventually get back to higher power states.
If we have sufficient power, we transition from minimum power mode to safe mode. In safe mode the flight computer actively performs attitude control with the wheels, imu, star trackers, and sun sensors to point at the sun and get as much power as possible. If we ever fall below a certain power threshold, we switch back into loadshed.
Nominal Data Transmission and Chunking
For most of the mission we expect to transmit 1000 bits per second, using Consultative Committee for Space Data Systems (CCSDS) compliant 1/2 Turbo Codes for encoding.
Throughout the mission we’ll still be dealing with high latency and potentially limited contact windows, so transport layer protocols like TCP that acknowledge each packet would significantly reduce the amount of data we can send.
As a result we’ve implemented a chunking system for telemetry and large files. At a high level, any file or telemetry can be sent as a Stream, and a Stream is composed of multiple chunks.
A single chunk looks like this:
And a stream looks like this:
Each chunk contains data and an application level CRC that we can use to ensure data integrity, and each stream contains an expected number of chunks and a hash of all the data that we’d expect to aggregate when the stream finishes.
When a client receives a chunk, it stores the chunk in a chunk database, which is essentially a memory mapped file. If the client - like AstroForge ground software - is trying to download a stream and hasn’t received any chunks for awhile, it can re-request the chunks it's missing.
If our connection is perfect, we’ll get the stream and all the chunks without any back and forth communication. But we can still get all of our data if any is missing and be sure we got it by comparing the hash of the data we have with the hash we received from the sender.
How do we know the software works?

Flight software is tested in many different environments before launch. Everything from frequent and quick unit tests to long duration hardware-in-the-loop tests are useful to make sure our software will work as expected after launch.
The lowest level of testing fidelity is unit tests. Unit tests exercise the behavior of libraries and low level logic. We take a function, give it some inputs and make sure that it produced the expected outputs. However, unit tests alone won’t catch issues caused by interaction between different pieces of software. Unit tests also won’t catch problems arising from interactions between the software and actual inputs from a sensor or actuator.
A higher fidelity way to run tests is with software in the loop (SITL) tests. In SITL, the software runs in a virtual machine or system container and the computer, the peripherals, physics, and everything the software interacts with is simulated. The software might think it’s spinning a reaction wheel, but the data its sending is intercepted by a reaction wheel emulator that responds as the reaction wheel would. When the reaction wheel spins, a physics simulation sends data through simulated sensors to make the software think the spacecraft is now spinning.
Hardware-in-the-loop (HITL) tests involve running the software on the actual computers and some of the avionics we will use in flight with physics simulations in the loop. Unlike SITL, on HITL we can see exactly how the processes and other compute is running on the real hardware, and get an accurate picture of the latency of reading sensors and commanding actuators. HITL tests are our best way to understand how we might expect our software to work in real flight.
There are two reasons why we still want to use SITL tests even when we have HITL. The first reason is that HITL is expensive and resources are limited. On DeepSpace-2, we only have one HITL and its used for both development and regression testing. Software in the loop tests can be time consuming to develop, but once they work they’re very cheap to run - we run multiple SITL tests in parallel on every code change before it’s merged into our main branch. We only run automated HITLs a couple times a day with code that’s already been merged.
The second reason why software in the loop testing is valuable is that it enables testing failures that would be dangerous to simulate in HITL. A battery failure is very dangerous and could cause a fire or other serious problem, if we do have a battery failure we want our software to take that battery off the bus so we isolate damage to the spacecraft. In SITL we can just simulate the inputs we’d expect when our batteries have failed, while doing a similar test in HITL requires careful monitoring and planning.
It’s rare for software to work perfectly on the first try, and flight software is no different. But with well-designed tests we can gather verification evidence, identify problems, and gather verification evidence again until our software is robust to many kinds of failure. From radiation to comms to the inability to physically access the spacecraft after launch, there are many unique challenges in operating in the space domain. But if we get it right, the result will be the same as what humans have been doing for a very long time - to find materials in new places - and hopefully put them to good use.